
Today's Obsidian Trick - Track task progress across files

Until today, I was able in Obsidian to track the progress of closing tasks in a single file at a time via progressbar, like so:
`= "<progress value='" + (length(filter(this.file.tasks.completed, (t) => t = true)) / length(this.file.tasks.text)) * 100 + "' max='100'></progress>" + " " + round((length(filter(this.file.tasks.completed, (t) => t = true)) / length(this.file.tasks.text)) * 100, 2) + "% completed"`
This is a one-liner that tracks the progress of all tasks in a single file, and its result would look like this:

It's great if you have like a central file. However it has at least three drawbacks I could see:
- You need to refresh the page each time you change a task's status. Otherwise, the progress value remains the same. This is well known and it happens because the calculation is mate when the file is opened.
- You need to open each file containing tasks (and replicate the code around
- It doesn't work with
dataviewTASKviews.
Listing tasks
I do have multiple files with tasks and I have a 'concentrator' file with a TASK listing like so:
TASK
FROM "Projects"
WHERE !completed
GROUP BY file.link
This will output all open tasks from all files, grouping them by file (so it's not a flat list of tasks).
You can change the criteria, add filters etc., based on the dataview documentation
Want more?
The concentrator has reached a rather large size of tasks, mainly because I always come up with new ideas in the TODO category, and I leave them until I have time to tackle them. So, I figured it's easier if I just go and split the concentrator into thematic tasks and track their progress. So, I've come up with this formula:
TABLE WITHOUT ID
"[[" + key + "]]" as Files,
length(rows) AS Total,
length(filter(rows.tasks, (r) => r.completed)) AS Completed,
"<progress max=100 value=" + (100 * length(filter(rows.tasks, (r) => r.completed)) / length(rows)) + ">" as Progress
FROM "Projects"
FLATTEN file.tasks as tasks
GROUP BY file.name
SORT key ASC
The result is something like:
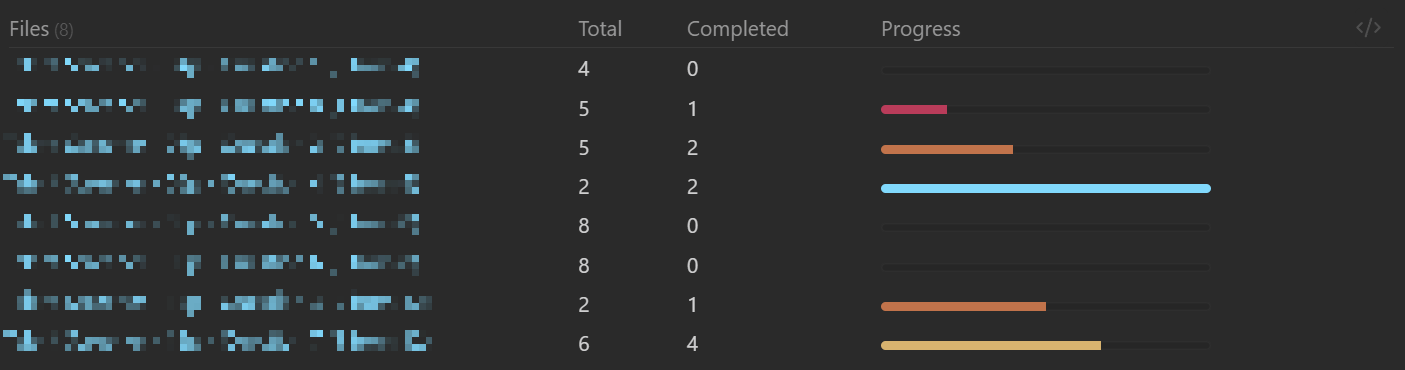
Each entry is a file that has tasks in it.
One thing to remember is that if a note has a TASK dataview query, it will not be picked up by the list, because the dataview queries are evaluated for the specific file, when it's opened.
HTH,