Insert in PostgreSQL in (Almost) Constant Time


One of the things I did was to write a script to insert records in a PostgreSQL database. The records have with a quite simple structure:
- id - char(20)
- content - XML field
- aside - XML field
I was working with a sample of 10,000 entries out of 40 million and the script went through several transformations:
- Version 1 - synchronised INSERT, pretty-printed DOM(*)
- Version 2 - synchronised INSERT, CR/LF-ed DOM(*) ( xml_source_string.replace(
><,> <) - Version 3 - buffered INSERT (commit every e.g. 1000 entries), CR/LF-ed DOM(*) - PostgreSQL XML type doesn't like XML content within a single line (compressed).
All variants used UPSERT statement for record insertion as indicated here, here and here-ish.
With the sample set, all variants showed very small variations in loading times, leading me to believe the insert time would be constant. However, when I tried to use a 1.6 million records as sample, the timer probes I had in the script painted a different picture (dots represent insert time/100 records):
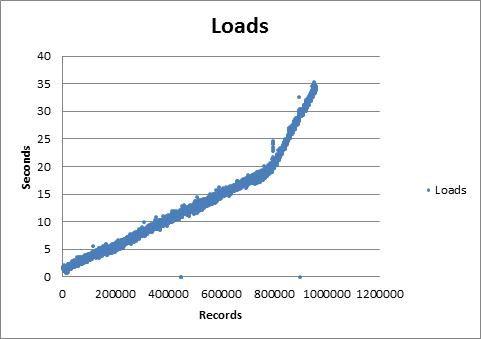
Whoa! Towards the end, it would take upwards of 30 seconds to insert 100 records! No wonder that the script didn't even finish after approx 5 days of running...
So... why would this be a problem? Well, 3 records/sec is slow. Loading the full table if the time would remain constant to this value would take approx 140 days. Ouch!
Speeding Up
In fairness, all the above results were obtained using the default settings in a Windows OS. Looking on the internet yielded several options for improvement:
- Don't index - Insert would result in a scan of the b-tree and insert in the b-tree too. Doing it may result in rebuilding the index. As a side note which eluded me at first: even primary keys create indexes!
- Do bulk inserts - Don't do atomic inserts. Ideally, prepare a statement, insert a set of records and perform a commit() for the set. There's a note that you should tune the size of the committed set to be less than a page (8K according to documentation).
- Vacuum - Set up auto vacuum , because it allocates more disk space for the table (default value is 0.2% of the current size of the table, but it can be tuned. A recommendation was to trigger autovacuum often.
- Use COPY statements - use COPY to perform something like a raw INSERT, rather that insert itself.
First option was already implemented (no indices). Second option is not really applicable because the XML entries are all larger than 8K. Even running the third option did not result in noticeable improvements.
Solution
The only variant which I did not try was the COPY command. Apparently, just by running COPY instead of INSERT, there is a significant speed-up. So, I've modified the script to:
- Version 5 - buffered COPY (commit every e.g. 1000 entries), CR/LF-ed DOM(+)
- Version 5 - buffered COPY (commit every e.g. 1000 entries), CR/LF-ed escaped DOM(+)
(+) - COPY is somewhat of a raw command and passing the buffer to the psycopg's copy_from() statement resulted in errors when e.g. a '\v' sequence would pop in because it would be escaped into a 0x0b character.
The python script would be something like:
# Initialisations
#
buf = StringIO()
count = 0
cursor = connection.cursor()
while has_entries:
id, content, aside = read_entry()
buf.write('%d\t%s\t%s\n' % (id, content, aside))
# Every 1000 entries, do a COPY and reinitalise the buffer
#
if count % 1000 == 0:
buf.flush()
buf.seek(0)
cursor.copy_from(
buf, '"MY_TABLE"',
columns=('id', 'content', 'aside')
)
buf.close()
# New buffer
buf = StringIO()
count += 1
# Copy the leftovers
#
cursor.copy_from(
buf, '"MY_TABLE"',
columns=('id', 'content', 'aside')
)
In other words, while we items to insert, read the item, process it and add it to the StringIO buffer. Every 1000 items, copy what we have in the buffer to the database. Be careful that the buffer is a TAB-separated table so, in the XML you'd need to replace the "\n" and "\t" symbols with spaces. As mentioned above, you also need to escape the string (replace "" with "") because it's un-escaped when passed to the COPY statement.
I've used StringIO to avoid creating files in the file system.
About Performance
Well, with the COPY variant, the insert time has halved for the sample (approx 0.6s instead 1.2s per 100 records). Also, when running the full 1.6M samples, the scatter graph of read times vs. DB insert times looks like this:
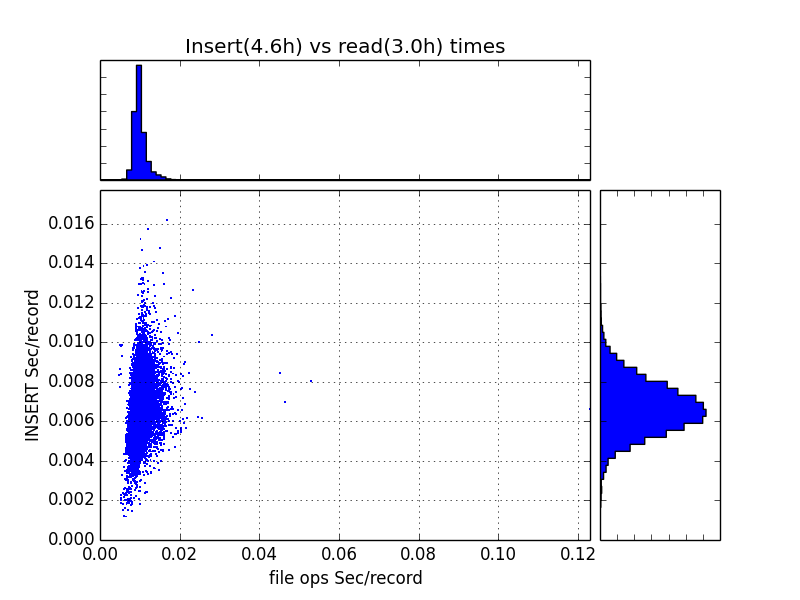
This means that load times are stationary at around 150 records/s (or 0.0065s/record).

This finding raises another bunch of questions, like since we'll need a relational model out of this, we may skip the XML load altogether and use the COPY statement straight in the relational representation...
HTH,

